What:
High Performance Machine Learning: Your model, with billions of weights, may not fit in a single GPU’s memory.
- We split the training data into shards.
- We clone the model and put a clone in every GPU we have.
- We train each model on its corresponding shard of training data, each computing gradients (loss) independently.
- We sync the gradients periodically.
- Allows scaling with multiple GPUs and minimal code changes
How to Sync Gradients?
Historically, two methods:
1. Parameter Sever:
A designated CPU - Processor Components gets sent each GPU’s gradient matrices. It adds them up, divides by and returns back the averaged out gradient.
This fails because of bandwidth bottleneck of GPUs sending GBs of gradients.
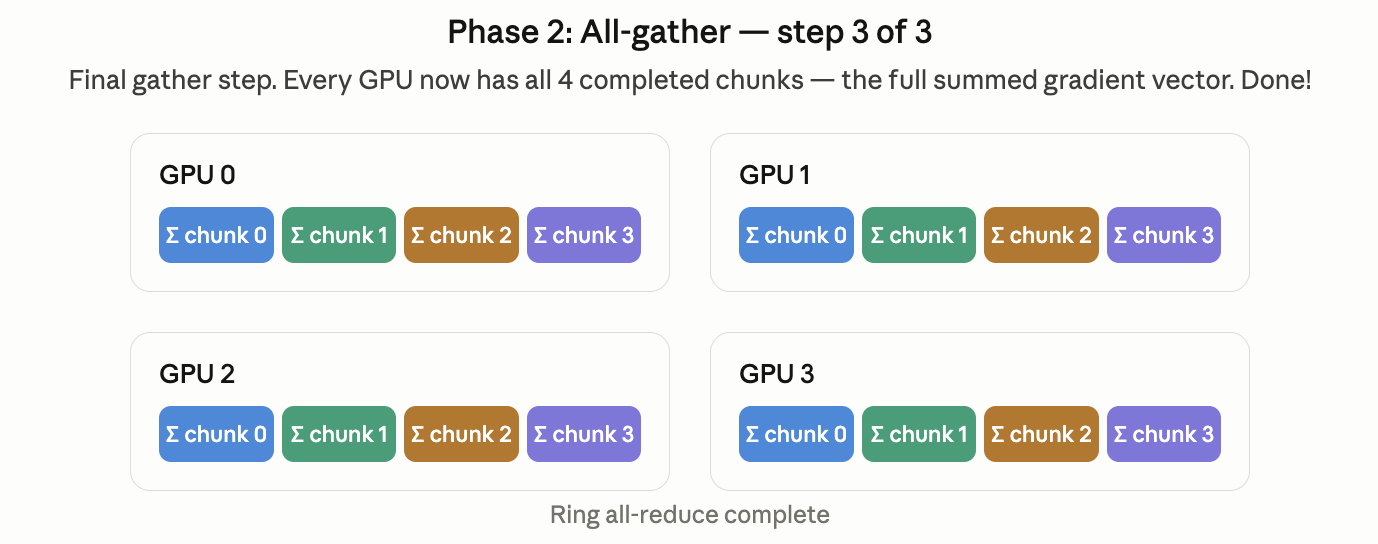
2. All-Reduce (HPC):
- You chunk your gradients file into chunks (where is the amount of GPUs you have).
- Each GPU sends a portion to the next GPU in the circle. (GPU 1 sends chunk 1 to GPU 2. GPU 2 sends chunk 2 to GPU3)
- They then send the chunk they just received to the next GPU in the ring as well.
- They repeat that until chunks have been sent
- All GPUs have a single (different) chunk fully complete.
- They then send that compute chunk forward. They repeat times.


Data Parallelism vs Distributed Data Parallelism (DP vs DDP):
- DP works in a single (multi-threaded) Python process.
- DDP spawns independent Python processes for each GPU, scaling across multiple nodes.