What:
It’s a family of 2-part Neural Network architectures:
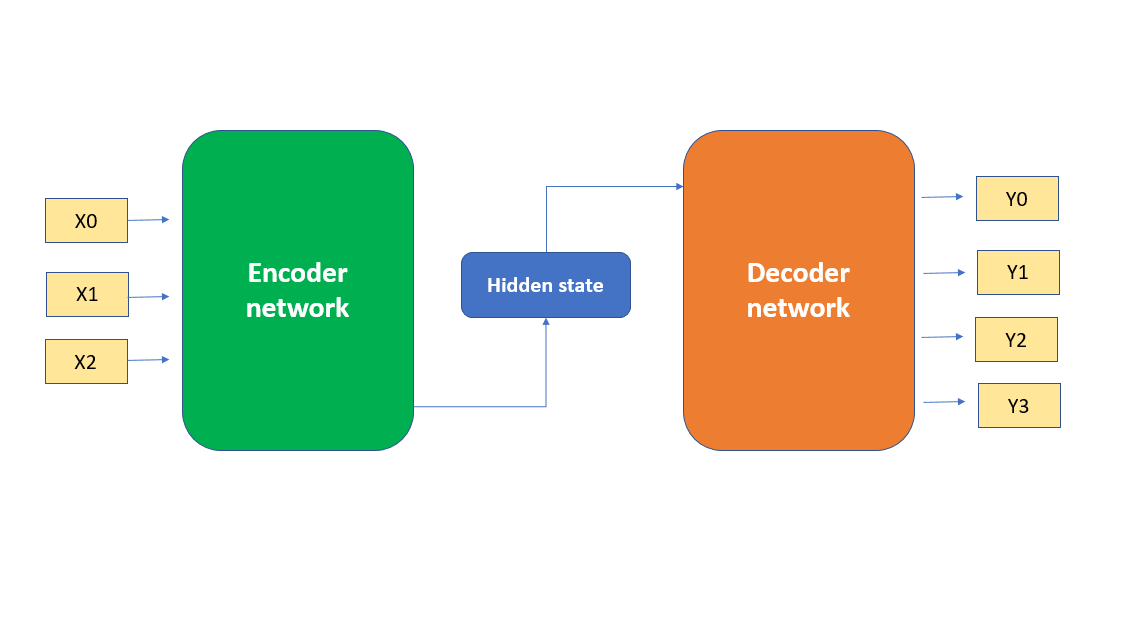
- You take input data and pass it into an encoder network.
- The encoder turns it into some latent representation (i.e. compressed vector(s) that represent the input)
- You then pass that hidden state into a decoder network, which transforms it into the output.
E.g. It would be like passing English text into the encoder, it’s transformed into the abstract, compressed meaning of the sentence, and then the decoder model transforms that into a French sentence.
The inherent drawback is: What if your idea can’t be compressed into latent space? You might end up losing a lot of information in that compression.
Cross-Attention:
In normal attention, the model attends to itself. So a sequence like “the lazy dog”, “lazy” would attend heavily to dog, but not so much “the”.
But cross attention, you work by attending across the network. So the decoder’s sequence may attend to the encoder’s sequence to decide what information to focus on. It’s essential for tasks where input and output are different sequences. (E.g. French input → English output)
This is relevant specifically to all encoder-decoder transformers.
Encoder Only 🆚 Decoder Only 🆚 Encoder-Decoders Learning Styles:
- Encoder only: You exclusively encode an input into latent space. Typically, you slap a classification head on top of this (either at token level or span level). You can now spam detection, NER and more!
- Works by masking certain words and then predicting the missing one - primarily training the encoder in the process.
- Decoder only: Takes an input, and predicts another vector. Typically, you can put that output vector back into the input and predict another vector (Auto-Regressive - ChatGPT)
- It’s only self-attention
- Encoder-Decoders: A family of models. This entire page is about it lol.
Types of Encoder-Decoders:
Auto-Encoders:
- Confusingly named, these are E-D models whereby the decoder is trying to reconstruct the exact input from the latent vector.
- This is useful for Image denoising, anomaly detection, image (re?)generation.
- The name comes from them Auto-Encoding themselves.
Seq2Seq:
- The decoder’s constructing a different sequence to the input.
- Uses similar concepts to MLM to train the decoder.
- Good for Summarisation, translation etc.
- Critically, in Seq2Seq transformers, this is an Auto-Regressive task.
Architecturally, they’re both a similar skeleton. Encode → Latent representation → Decode.
Examples:
- Recurrent Neural Networks (RNN)
- The original Transformer